At Betfair our read services are struck with billions of requests per day, they are not evenly distributed either. These requests will arrive in huge spikes of traffic during key sporting events, putting our customer facing services under huge pressure during sustained time periods throughout the day. We develop our systems to cater for this demand, keeping true to our latency SLA’s all the while operating without downtime. Unlike comparable trading platforms used in the financial world, we don’t have the option of closing trading at 5pm – sporting events occur around the clock, every day.
When we talk about read services, we are referring to anything that is presented, in real-time to customers – either through the API or via our online channels. Notably, our price read services. They were the first to move to the streaming model. If you are not familiar with financial trading, price read services present ‘ticks’ on a market to our customers – billions of them. Ticks are price/volume pairings for a given selection on a market. See below.
At any given time we are operating around 40,000-50,000 markets on the Exchange, each market averages 3000 ticks with changes to the market view occurring thousands of times per second for popular sporting events. Presenting an accurate view of this data is a real challenge and as demand for our services only ever increases our legacy architecture started to creak, and here’s why:
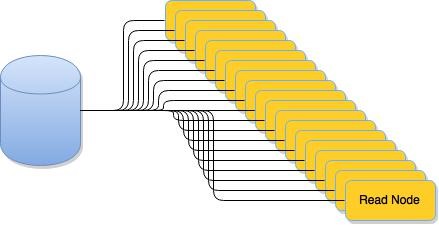
In our traditional model of scaling, we would add read nodes to our cluster (a read node being an in- memory cache of all exchange market activity at a given point in time), all of which were polling our Oracle RDBMS. The demand on our services reached a stage that our Oracle solution could no longer scale to meet our demand, in fact our read services were actively destroying the performance of other services using the database. This put us in a difficult position, more customers wanted to use our services but the database needed us to use less connections – we could no longer scale.
Naturally, being the forward thinking people we are, we had pre-empted this sometime prior to it occurring and development had been underway for a new solution for some time. The answer – we needed to turn our data store into a data stream. For the time being, the database was going to be our single point of truth – we were slowly migrating everything away from it but that journey wasn’t going to be complete in time to solve our immediate price read problem. We had been investigating an approach to stream our data out of the database through a LinkedIn innovation called Kafka. Kafka is a durable, scale-able messaging solution but think of it more like a distributed commit log that consumers can effectively tail for changes.
It was ideal for us, our services would scale infinitely as they could subscribe to the Kafka stream, no longer polling the DB directly. We would only ever need one node polling the database and publishing to the Kafka stream. It was durable – so if our nodes needed to reload their cache (say, after a restart), they could back-load the Kafka commit log and catch-up to the current point in time before coming back into service. It could also easily handle the volume that we were going to throw at it – on a side note, there is a great blog on Kafka’s performance metrics here.
Testing in Production?
The hardest part was yet to come, how do you wholesale replace a business critical tech without down time? Well, we had actually been testing in production for some time, our nodes were not customer facing but they were updating their caches using production data. We did this to ensure that the latency was equal to that of the old DB back-end read nodes and that the data was consistent between the old and new clusters.
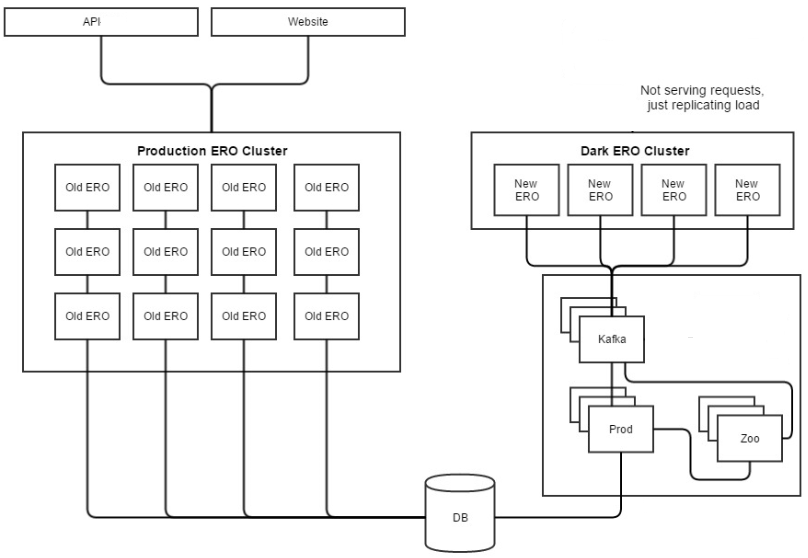
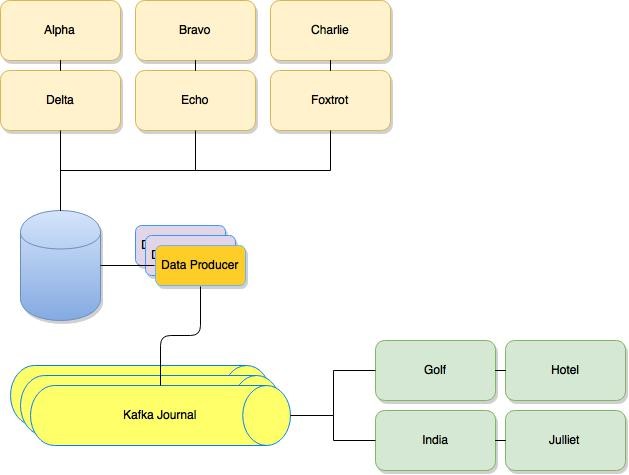
Above is a copy of the actual deployment plan we used for production testing. As all we were doing was adding one additional ‘data node’ to read from the DB, we are able to build up the new cluster without impacting the rest of the production estate. The ‘Zoo’ node is reference to the Zookeeper cluster that we were using to orchestrate resiliency between the Kafka instances. ERO is an acronym of Exchange Read Only aka a read node and ‘Prod’ refers to the data producing node that is publishing to Kafka from the DB.
Now that we were operating ‘dark’ in production without issue, we needed to focus on switching off the old estate and bringing the new estate in to service. While we were confident with our testing, we still didn’t just want to switch the old cluster off and turn the new cluster on. Firstly, that would result in downtime – albeit only a few seconds, but that is still not an acceptable level of disruption to our customers. Secondly, if we had missed something in testing, all of our customers would be affected and we would introduce further downtime by having to roll back.
Deployment Zones
Our read service estate is huge and even with continuous delivery pipelines, deployment of these services still takes a fair amount of time. To limit the impact of potential installation errors on our customers, we divided our estate up into deployment zones. Deployment zones contained an equal number of nodes divided up amongst the cluster.
As we invested considerable effort in bringing the latency of the new read services into line with that of the new services, we could run them, customer facing, in parallel. Which is exactly what we did. One deployment zone by one, we added the new nodes to the cluster. We started with one, analysed the results, monitored the twitter feed for customer feedback and slowly gained confidence. Once we were happy we added more and repeated the process, increasing the number of deployment zones and frequency with each release.
Eventually we reached the stage whereby 50% of our read service estate was running on the Kafka backed stream. We had scaled our cluster without impacting contention on the database and our customers hadn’t noticed any service deprecation or latency changes. Success! Finally, we were happy that the new solution could wholesale replace the old. We began migrating all of the old estate deployment zones to the stream backed model.
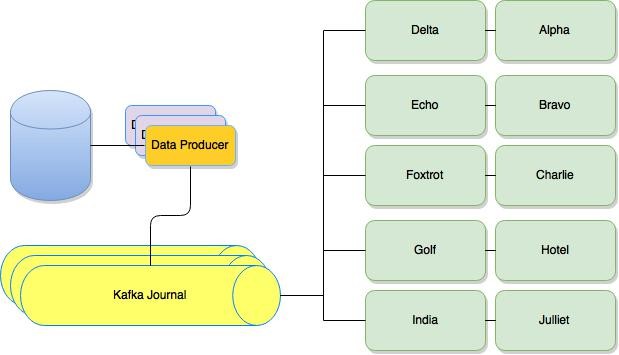
We have since been running our price read estate on Kafka without any major problems, what’s more – we have been able to seamlessly scale the cluster to cater for some of our busiest periods using our CD tooling. All of the prices you see on the Betfair Exchange site are being streamed to you though Kafka, the same technology that pushes the various posts and updates to you on LinkedIn.
Of course, we still have a lot more work to do. Having been operational with Kafka for some time, we have identified some changes to the way that we stream our data. As such, we are actively developing a new journaling solution that will offer enhanced performance and data consistency improvements beyond that of the Kafka framework. A challenge that our technical teams are relishing.
