This is the story of how we built and scaled our unified sports catalogue that encompasses all the sports, events, competitions and markets on offer to our betting customers across the Flutter group, including The Betfair Exchange, Betfair International and Italian Sportsbooks, Paddypower Sportsbook and more recently including the Fanduel sportsbooks across several states in the US. This details the journey from a single brand single product DB centric model to a more event driven multi brand multi product model that is deployed across the globe over several public and private cloud implementations. This also describes how this initiative played a vital role in the successful rollout of Flutter’s own Global Betting Platform to several brands, as the business grew to include multiple brands over the years.
Before talking about how we expose the product catalogue, a quick intro into how the product catalogue is actually created and managed through its lifecycle. We receive the feeds and notifications from various official providers and partners about the scheduling of real world events, like football fixtures or horse races, over vastly different mechanisms, ranging from files being FTP’d, polling APIs and push interfaces. As you can imagine sifting through all of this humongous amount of real world information and distilling them into a set of unique betting events and markets, is a complicated task in itself and probably warrants a description in a separate blog in itself. But suffice to say for now, that the data goes through several layers of filtering, transformations and distillations over several platforms before being clarified into a single generic model that is stored in a centralised Oracle DB.
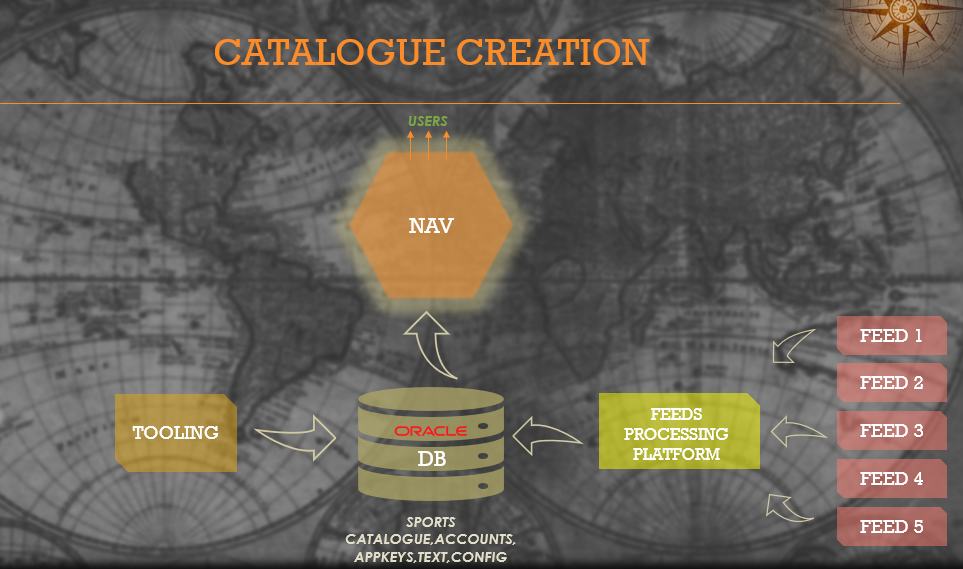
Now the job is only half done at this point, as this unified model can only be generic enough to a certain extent, because each sport is structurally different. As a result the underlying data gets spread across a multitude of DB tables, some sport agnostic and some specific and making sense of the collective view of these couple of dozen tables becomes a complex challenge. There was a micro service we built for this purpose a few years ago called MGA (Market Global Application), that pulls the data periodically from all of these tables and creates an in memory model of this entire catalogue, and exposes the same to other applications via a well defined query API. This is the starting point for all our customer facing channels and APIs to discover and navigate the content on offer. This interface has evolved over the years to support more sophisticated query and aggregation capabilities from supporting canned prebuilt queries, to a directed acyclic graph that can be traversed over an API to an uber flexible faceted search api, but by and large the source of the data and internal modelling has remained unchanged. In order to scale to support multiple products at this point we simply created multiple clusters of the same api pointing to the common catalogue DB and some product specific data sources. The main drawback with this approach ofcourse is the fact that the scale was completely limited by the number of connections that could be opened up to the underlying DB, and could not be scaled beyond a certain limit without stressing the whole system.
It all started here
All that changed about 2 years ago, when following the acquisition of Fanduel business in the US by PaddyPower Betfair, we started thinking about how we build and deploy a truly Global Betting Platform ( GBP ) into the US, which is predominantly the PPB version of Sportsbook platform, but with enough abstractions and generalisations to allow the deployment to be customised and run anywhere in the world, with minimal connections back to the “mothership” estate running in Dublin, Ireland on a private cloud. Since this connection is over the public internet the goal was to minimise the interactions and amount of data being shipped over the weak link. At this point we could have done a lift and shift the above Navigation capability we had in PPB onto US soil, and create a deep rooted connection back into Dublin, which was an easy and cost effective thing to achieve. But the ambitious growth plans for our Fanduel business would have meant that the connection back into our UK estate would have quickly become a bottleneck and resulted in poor customer experience , whilst also increasing the load on our already creaking legacy DBs exponentially as more states came on board.
The Idea
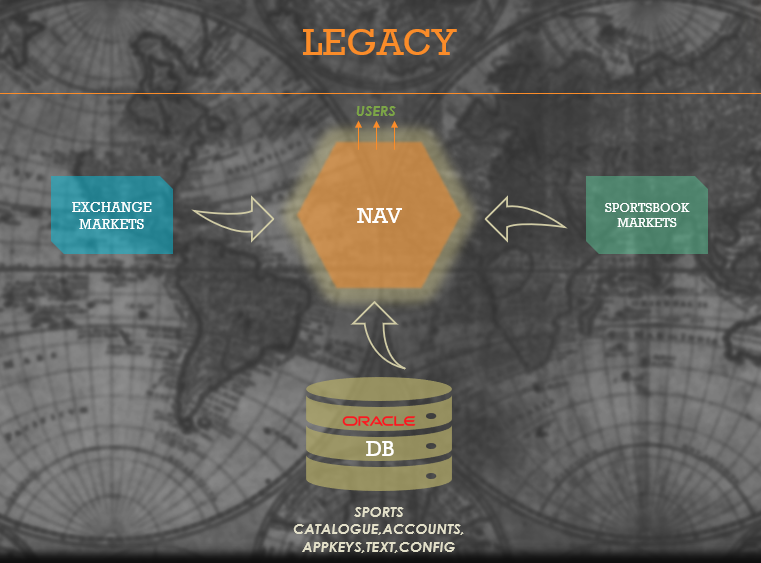

At this point we decided we are going to split the Catalogue navigation capability down the middle into two halves, one half performing the data aggregation, cleansing, efficient transformations and exposing the whole Catalogue model via a Kafka conduit and the other half performing the function of a fast query API based on existing interfaces and contracts that were already well known and had ready integrations, which sourced its catalogue data from the Kafka stream. At the outset, this was a very simple idea, but the complexity of the underlying data model meant that building the producer stack and modelling the Catalogue data in a way that works fast and efficiently over even the weakest of links, and then rewriting the Navigation query API completely to use the new data sources, was a lot harder than it seemed. There was a huge amount of work needed to validate the colossal data model, and make sure there are no deviations from the existing contracts. A significant amount of effort was also spent to make sure the re-assembly of data model on the other side of the pond was robust and resilient enough, to provide consistent data at all times. All this had to be achieved without compromising on the strict SLAs for data availability ( markets need to be available for customers to bet on within a few minutes some times less than a minute after they get created in our system to maximise our revenues ) and the strict latency SLAs on the API ( our customers typically expect responses within a few tens of milliseconds even while serving tens of thousands of requests per second ). We decided to call this generation of stream based navigation stack simply SCAN, a more intuitive and friendly name than the ominous sounding MGA. We finally managed to get all this done and integrated into our first Fanduel state ready for testing in Feb 2020. That was a huge milestone as we proved the new architecture and laid the foundations for future scale out.
First cross brand rollout
The job was not done. Of what use was 8 months of hardwork to re-engineer a core part of our stack, if it only fitted one use case across the pond, while the rest of the brands and products are still using legacy model, of sourcing the data directly from the DB. At this point there was some momentum building within Betfair to try and reduce our dependency on legacy DBs for cost as well as scale reasons. There was also a high profile project that had just kicked off to completely rebuild the mobile solution for Betfair and bring it to the 21st century inline with the likes of Netflix and Amazon. This needed a new backend Catalogue Navigation API cluster to be built to support some bespoke functional and performance requirements. This was a problem, but this was also an opportunity. We took the SCAN solution that we built for Fanduel and decided to port that into PPB estate specifically for this project, with the added benefit that we would not be adding any additional footprint and load on our DBs. Killing two birds with one stone, meant we were able to fast track the adoption of the new stream based navigation stack and also proved out the capability to the business that initial investment in re-engineering this stack, has compounded in value as we rolled this out to the BF estate for the first time. This was June 2020.
Back to where it began
Once this was proven out, the next step was to roll this out to the rest of BF and PP estate, which included 4 separate installations or flavours as we call them, each with different data sources, slightly different configuration and modes of working. At the same time there were multiple other projects in flight that were asking for improvements and feature additions on existing stack, so we took the approach to draw a line in the sand and say, from a point in time onwards, feature additions will happen on new stack only. This ensured that we focused on one path forward and also gave the impetus to reduce the period of time where legacy and new stacks needed to be maintained in parallel. This also gave us the opportunity to use those projects as vehicles to make real technological progress. The main challenge here was to ensure a seamless rollout, since the existing stack was heavily in use and we had to be extra careful to make sure there was minimal customer impact as we did this. To do this, we came up with a strategy to add the new stack under existing load balancer vips, and by adjusting the weights we were able to gradually throttle the traffic up onto the new hosts, while majority of traffic was still being served on the legacy stack. This way we could spot potential issues early and throttle down quickly to reduce any customer impact, and allowed us to tweak and fix things for each flavour in a controlled way. The process was a bit longer than ideal but being able to have full control of the flow of traffic from old to new stack meant we could manage this as seamlessly as we could, which was paramount. The whole process took a few months and we were finished with rollout on all 3 BF installations by Jan 2021.
One Final Push
This left us with a single PaddyPower flavour to be upgraded to SCAN before Spring Racing in March 2021. For those who are not familiar with the domain, Spring Racing is one of the busiest times of the year for us, where the customers interest in our products are at their peak through the Cheltenham and Grand National periods. As such the load and performance requirements on our systems are especially high during this period and we do a lot of work to prepare for this period. From ensuring general hygiene, to performing focussed load tests on our systems, identifying and removing bottlenecks, and scaling out our systems to match the projected loads where needed. To make things interesting, the projected load on our PP stack this year, had been especially high compared to previous years, because of a variety of reasons to do with Covid and general growth. So the ask from the business was to scale out our systems to 3x the capacity we had in previous year. Normally this would have caused an increase in the load/footprint on our DBs linearly, but because of the new stream based stack, we could just scale out to 3x capacity to support more headroom, with no impact on underlying systems. Further more, we even went ahead and scaled out to 5x to have additional operational headroom. We had some challenges in this, to make sure we minimised the load exerted on any downstream dependencies as we did this and to make much better use of our virtualisation infrastructure to reduce contention at CPU level, but overall the tests proved that the scale and capacity was created within space of a few weeks.
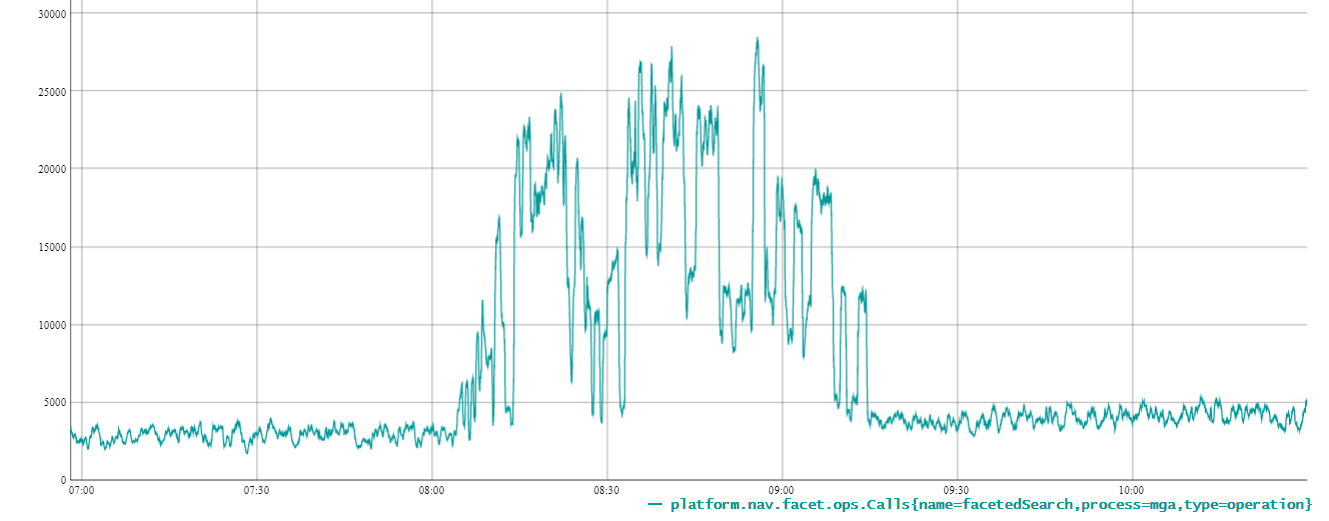
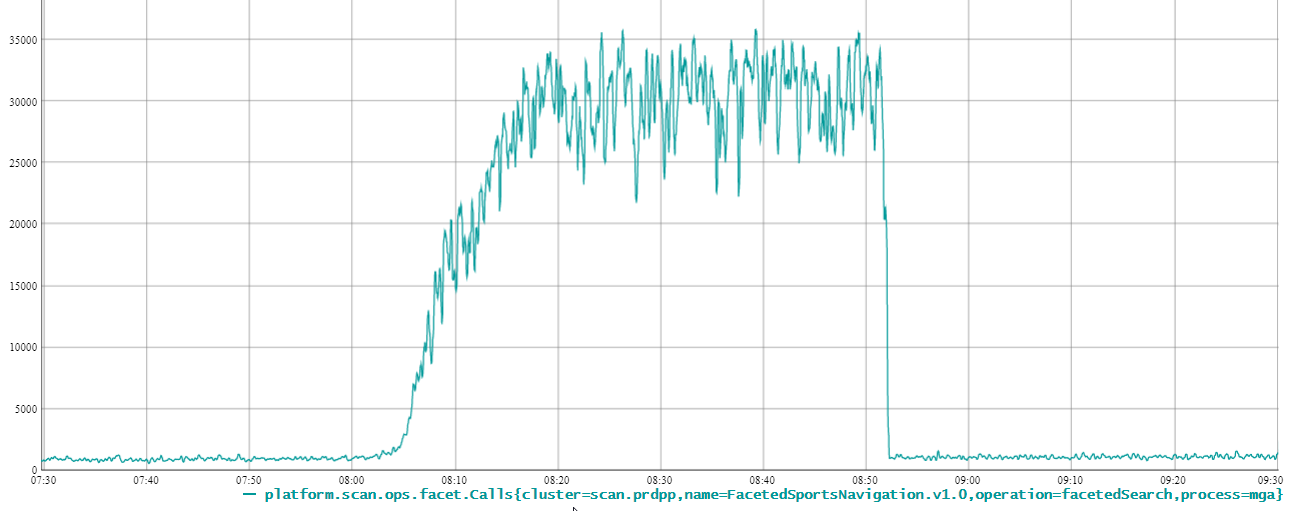
As you can see on the first image while our legacy MGA stack got absolutely butchered in our early load tests at 20k req/s, the new SCAN stack on second image breezes through at 70k req/s across DCs.
The real test was ahead of us in Spring Racing 2021, but we were confident that the load and the capacity we created put us in a good position to be ready for any uplift we see in traffic. To give an idea of the scale, 2 years ago we had 56 hosts serving 2 brands, with an overall footprint of upto ~1400 DB connections while today we have 80 hosts ( and more being added as we speak ) across 3 brands, for an overall reduced footprint of upto ~100 DB connections, with ability to scale upto 5x capacity in some cases as stated above. Suffice to say kind of scale and capacity requirements we had for 2021, would not have been possible to be achieved with the legacy stack without putting significant risks on other parts of the system. In the end Spring Racing 2021 was a record breaking racing season for us in terms of customer interest and performance of our systems and the new stack pulled through without a glitch.
Looking Back
Looking back at this nearly 1.5 years of work, through all the hurdles and challenges that we had to overcome, with covid, the internal and external deadlines, competing scheduling and simply engineering challenge to get this built and rolled out to customers while minimising the impact, and scaling it out in time for what was to be a record breaking spring racing season, its a mixture relief, triumph, regret at missed opportunities and excitement about what this has unlocked for the business. There is a lot that we got right, a few situations that could have been handled differently but above all it all came together well in the end to provide a stable experience to our customers, and provided a reliable foundation for building other products and features on in future. Further more, there were products and capabilities that were built on top the work we did, that simply could not have been built earlier, further reaffirming the foundations and capabilities we are building are taking our business in the right direction. Some key takeaways for us that resonates through all this,
Real progress sometimes starts with really a simple idea.
A simple idea still needs great execution to give the desired outcomes, with a healthy dose of doggedness
Focus on building capabilities rather than features or point solutions.
With the big picture thinking it makes it easier to align capabilities to more than one product or brand, making the case for the investment and end business value stronger as time goes by.
Timing is crucial.
Aligning things at the right time, at the right pace and at the right place makes it far more easier and efficient to achieve progress. In our case multiple projects were aligned at the right time to add momentum to the rollout, much quicker than we could otherwise
Business buy-in.
Highlighting the long term benefits of investing in evolutionary engineering efforts, in the right forums and in the right formats, is crucial to getting the business buy in for any such longer term initiatives. In our case it was a process we had to go through, but these conversations became lot easier to have towards the end than at the beginning of initiatives.
Future
Having said all that, this is not the end of the story. There is much to be improved in this area, by abstracting the creation processes, and making the whole event path more efficient by representing messages as deltas rather than snapshots. We will continue to focus on using these new capabilities to on board more products, brands as part of our Global Betting Platform work, some of which is already in progress. Nonetheless this is an important milestone in the evolution of Catalogue Navigation area, one that was envisaged, engineered and delivered by Betfair Exchange Platform for the wider Flutter group. We are excited about the possibilities it will unlock for the wider business.
None of this would have been possible without the guidance and support of our Chief Architect Matt Cobley and especially the world class engineering team that’s built around Tetyana Dudka and Neil Harrington, led by Umar Ayaz, with Alex Sklikas, Konstantin Anashkov, Anton Vesty, Nikita Larin, Bogdan Martinez, Chris Villegas and Chrysanthi Isaakidou.

